
"你是否曾想过如何在你的Python脚本中访问微软SharePoint?
本教程正是针对这个问题。
你将能够通过使用一个叫做Connect Bridge的工具,以一种简单的方式来完成。"
介紹
本文介绍了如何制作 Python连接到SharePoint即如何从Python语言脚本内访问微软SharePoint系统(2010、2013或2019)的数据(使用3.7版本)。数据传输是通过ODBC层进行的。我们已经在Python中使用 pyodbc模块 版本:4.0.26。4.0.26.
需要注意的是,在本文中,我们使用的是一款名为Connect Bridge的商业产品。事实上,这就是Python / SharePoint集成的原因,通过允许数据通信的方式,你可以确信你不会弄乱SharePoint方面(相信我,这非常重要)。您可以 获得免费试用 为Connect Bridge,所以你可以亲自尝试这些。
这个 "Connect Bridge "是什么?
我很高兴你问了这个问题! Connect Bridge 是一个由Connecting Software开发的集成平台,允许你通过ODBC驱动、JDBC驱动或Web服务连接任何软件。该工具的架构的总体概况在这个客户-服务器方案图上。
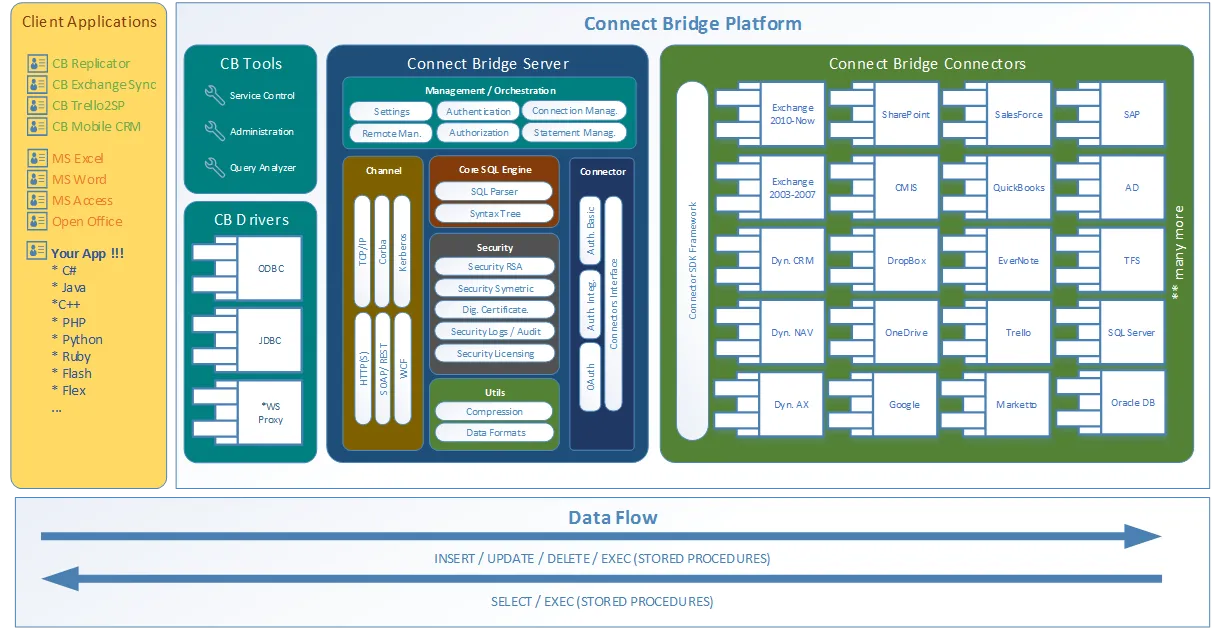
Connect Bridge 集成平台架构
正如你在架构图上看到的那样,该工具不仅可以用于从Python脚本中访问微软SharePoint数据,还可以从微软Exchange和微软Dynamics CRM中抓取/输入数据。
目的--使用Python获得SharePoint的数据
我们工作的目的是创建一个Python脚本,使我们能够通过Connect Bridge与SharePoint对话。
我们使用SharePoint,但也可以使用类似的逻辑来连接到 微软Exchange 或到像Salesforce或Dynamics这样的CRM。
开始吧...
现在让我们开始这个教程吧!我们的目标是创建一个简单的Python脚本,访问一个SharePoint实例。我们假设SharePoint实例已经存在(请确保你手头有你的登录凭证)。这些是你需要遵循的简单步骤。
1.申请 免费试用 并安装Connect Bridge
2. 安装 适用于Windows的Python ver.3.7+.请注意,为了使编写、运行和调试我的脚本更加容易,我们使用了 Liclipse 5.2.4的pydev插件,但这当然是可选的。你可以使用你选择的编辑器。
3. 安装 pyodbc模块 4.0.26+
4. 运行Connect Bridge管理工作室和
4.1. 为SharePoint添加一个账户(账户-添加账户)。在这里,你将需要我们前面提到的那些凭证。
4.2. 打开 新查询 选项,然后是 连接浏览器.找到 SharePoint连接器 并打开它,直到你看到 默认连接.右键单击它并选择 获取连接字符串.然后复制ODBC的连接字符串。你将需要它来把它传递给脚本。
4.3. 使用 "新建查询 "选项来测试一个查询,该查询将访问你在SharePoint中需要的内容。我们将在这里做一个查询的例子,但你应该在这里输入你在SharePoint中寻找的东西。一旦你点击了 新查询,打开 连接浏览器.找到 SharePoint连接器 并打开它,直到你看到 桌子 选项。你会发现模式中包含一个名为 Site_Pages 的 “表”,因此我们可以将查询构造为
SELECT UniqueId, ContentType, Created, Modified, ContentVersion FROM Site_Pages LIMIT 10;
来选择SharePoint的前10个条目。 网站页面 列表。需要注意的是,尽管看起来我们好像直接使用了一个数据库,但事实并非如此。
Connect Bridge正在访问API,然后把它当作一个数据库来展示。一旦你有了你的查询,复制它,因为你也需要它来把它传递给脚本。
手把手教你写脚本!
我们解决方案中的核心文件,同时也是唯一的文件是CBQuery.py。完整的源代码在下面。请关注第70-92行,它描述了核心解决方案。下面是关于这个脚本如何工作的完整描述。
#!/usr/local/bin/python3.7
# encoding: utf-8
'''
CBQuery -- query data from, write data to SharePoint
CBQuery is a script that allows to run SQL queries via Connect Bridge ODBC driver
@author: Ana Neto and Michal Hainc
@copyright: 2019
@contact: ana@connecting-soiftware.com
@deffield updated: 04.07.2019
'''
import sys
import os
import pyodbc
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
__all__ = []
__version__ = 0.2
__date__ = '2019-07-04'
__updated__ = '2019-07-04'
DEBUG = 1
TESTRUN = 0
PROFILE = 0
class CLIError(Exception):
'''Generic exception to raise and log different fatal errors.'''
def __init__(self, msg):
super(CLIError).__init__(type(self))
self.msg = "E: %s" % msg
def __str__(self):
return self.msg
def __unicode__(self):
return self.msg
def main(argv=None): # IGNORE:C0111
'''Command line options.'''
if argv is None:
argv = sys.argv
else:
sys.argv.extend(argv)
program_name = os.path.basename(sys.argv[0])
program_version = "v%s" % __version__
program_build_date = str(__updated__)
program_version_message = '%%(prog)s %s (%s)' % (program_version, program_build_date)
program_shortdesc = __import__('__main__').__doc__.split("n")[1]
program_license = '''%s
Created by Ana Neto and Michal Hainc on %s.
Licensed under the Apache License 2.0
http://www.apache.org/licenses/LICENSE-2.0
Distributed on an "AS IS" basis without warranties
or conditions of any kind, either express or implied.
USAGE
''' % (program_shortdesc, str(__date__))
try:
# Setup argument parser
parser = ArgumentParser(description=program_license, formatter_class=RawDescriptionHelpFormatter)
parser.add_argument('connstr')
parser.add_argument('query')
# Process arguments
args = parser.parse_args()
query = args.query
connstr = args.connstr
conn = pyodbc.connect(connstr)
cursor = conn.cursor()
cursor.execute(query)
while 1:
row = None
try:
row = cursor.fetchone()
except:
print(sys.exc_info()[1])
break
if not row:
break
print(row)
except KeyboardInterrupt:
### handle keyboard interrupt ###
return 0
except:
print(sys.exc_info()[1])
#indent = len(program_name) * " "
#sys.stderr.write(program_name + ": " + repr(e) + "n")
#sys.stderr.write(indent + " for help use --help")
return 2
if __name__ == "__main__":
if TESTRUN:
import doctest
doctest.testmod()
if PROFILE:
import cProfile
import pstats
profile_filename = 'CBQuery_profile.txt'
cProfile.run('main()', profile_filename)
statsfile = open("profile_stats.txt", "wb")
p = pstats.Stats(profile_filename, stream=statsfile)
stats = p.strip_dirs().sort_stats('cumulative')
stats.print_stats()
statsfile.close()
sys.exit(0)
sys.exit(main())
这是我们的脚本在做什么。
- 第 71-80 行主要是从命令行参数输入中获取 connstr 和 query 变量。为此,我们使用了 pydev 的 argparse 脚本模板,以方便我的工作
- 变量 connstr 保存了 ODBC 连接字符串,我们将其传递给 pyodbc 模块以创建 ODBC 连接(保存在 conn 变量中)。
- 下一步,我们使用保存在 conn 中的连接打开一个数据库游标
- 连接存储在 conn 中,我们使用 conn 打开一个数据库游标
- 我们执行 SQL 查询(这是通过名为 query 的命令行参数传递的查询)
- 最后,我们使用 while 循环从游标中逐行读取结果。当 cursor.fetchone 返回 None 时,我们将中断循环
- 如果在获取 ODBC 数据的过程中出现异常,我们也会中断循环并将问题打印输出
- 如果 fetchone 方法成功并返回数据行,我们就将原始数据行打印到输出中。这是我们在本演示中的选择,但请注意,这可以是任何类型的输出......我们可以将其格式化为 xml 或 json、csv......或任何其他类型的数据交换格式。我们还可以简单地使用原始数据行对象,以便在进一步的代码中执行自定义任务。.
运行CBQuery.py脚本
我们知道,我们的CBQuery.py接受两个位置命令行参数:connstr和query。
我们需要从Connect Bridge管理工作室复制这些内容,如上所述(第4点)。
我们可以建立一个SharePoint联系人名单,并写一个条目吗?
现在,假设我们想在 SharePoint 中创建一个联系人列表,并在该列表中创建一个联系人。我们基本上需要遵循相同的流程,但要将查询改为使用 "存储过程"。同样,这个 "存储过程 "实际上将通过 API 访问 SharePoint,但它会将数据导入您指定的 SharePoint。下面是我们需要运行的查询:
EXEC SP_CREATE_TABLE 'MyContacts', 'This table was created using Connect Bridge', true, 'Contacts';
该查询创建了一个新的SharePoint列表(MyContacts),其描述将显示在SharePoint页面的快速启动栏中。
现在,我们需要调用以下查询来更新 Connect Bridge ODBC 模式对 SharePoint 模式的反映。这样,ODBC 客户端就能看到我们的新 “表 ”了。.
EXEC SP_UPDATE_SCHEMA;
在这一点上,我们可以在联系人列表中插入一个联系人条目。
INSERT INTO MyContacts (FirstName, LastName) VALUES ('Ana', 'Neto');
现在您应该可以在SharePoint用户界面上看到我们的条目和我们新的SharePoint列表。
我们可以通过运行以下查询选择我们刚刚创建的条目。
SELECT FirstName,LastName FROM MyContacts
上传和下载共享文件
为了上传共享文档,我们将使用现有的 SharePoint 列表 “文档 ”和 "存储过程 "SP_INSERT_SHAREDDOCUMENT。它需要的参数是
- 共享文件表名称
- 文件名
- 文件夹(相对路径,在服务器上)
- MIME 类型
- 文件数据
我们可以通过运行以下语句来插入文档。
EXEC SP_INSERT_SHAREDDOCUMENT
'Documents',
'hello2.txt',
'/Shared Documents/NewFolder',
'text/plain',
'SGVsbG8gV29ybGQ=';
如果你想事先检查该文件夹的存在,你可以运行该语句。
EXEC SP_ENSURE_FOLDER_PATH
'Documents',
'/NewFolder';
运行 SP_INSERT_SHAREDDOCUMENT 之后,我们可以通过运行语句来检查 “文档 ”表中是否存在该文档:
SELECT Id,Name FROM Documents;我们也可以通过运行语句从特定的文档库中下载特定文档的二进制内容。
EXEC SP_SAVE_SHAREDDOCUMENT_BY_ID 'Documents', 2; 这时你可以在SharePoint用户界面中检查共享文档的存在性
限制因素
到目前为止,我们只能在Windows操作系统上使用Connect Bridge工具,因为没有ODBC Linux客户端库(我们不确定这是否可能)。所以一定要在Windows机器上玩你的Python脚本。
结论
我们已经看到了如何使用Connect Bridge集成平台轻松地在Python中访问SharePoint数据。现在想象一下,你在这篇文章中看到的东西在微软Dynamics CRM和微软Exchange中也可以实现!是的,用Connect Bridge就可以做到这一点,方法也是类似的。
我可以向谁咨询问题?

作者 Ana Neto, 技术顾问 于 Connecting Software。
"自 1997 年以来,我一直是一名软件工程师,最近开始喜欢写作和公开演讲。您对本文有任何问题或评论吗?欢迎在下方留言!"
Comments 1
谢谢你的清晰解释!"。