
"PythonスクリプトでMicrosoft SharePointにアクセスする方法について疑問に思われたことはありませんか?
このチュートリアルでは、それだけを扱っています。
Connect Bridgeというツールを使えば、簡単にできるようになります。
序章
この記事では SharePointにPython接続つまり、Python言語スクリプト(バージョン3.7を使用)からMicrosoft SharePointシステム(2010年、2013年、2019年)のデータにアクセスする方法です。データ転送はODBCレイヤーを介して行われます。を使用してPythonでこれを実現しています。 パイodbcモジュール ver.4.0.26.
ここで注意したいのは、この記事ではConnect Bridgeという市販品を使用していることです。これは実は、SharePoint側をいじっていないことを確信した上でデータ通信を可能にすることで、Python / SharePointの連携を可能にしているのです(そして、信じてください、これは非常に重要です)。あなたは以下のことができます。 無料体験を受ける Connect Bridge用なので、全部自分で試してみてください。
この「Connect Bridge」とは何でしょうか?
よくぞ聞いてくれました! Connect Bridge は、Connecting Softwareが開発した統合プラットフォームで、ODBCドライバ、JDBCドライバ、Webサービスを通じて、あらゆるソフトウェアを接続することができます。このツールのアーキテクチャの概要は、このクライアント・サーバーシナリオ図にあります。
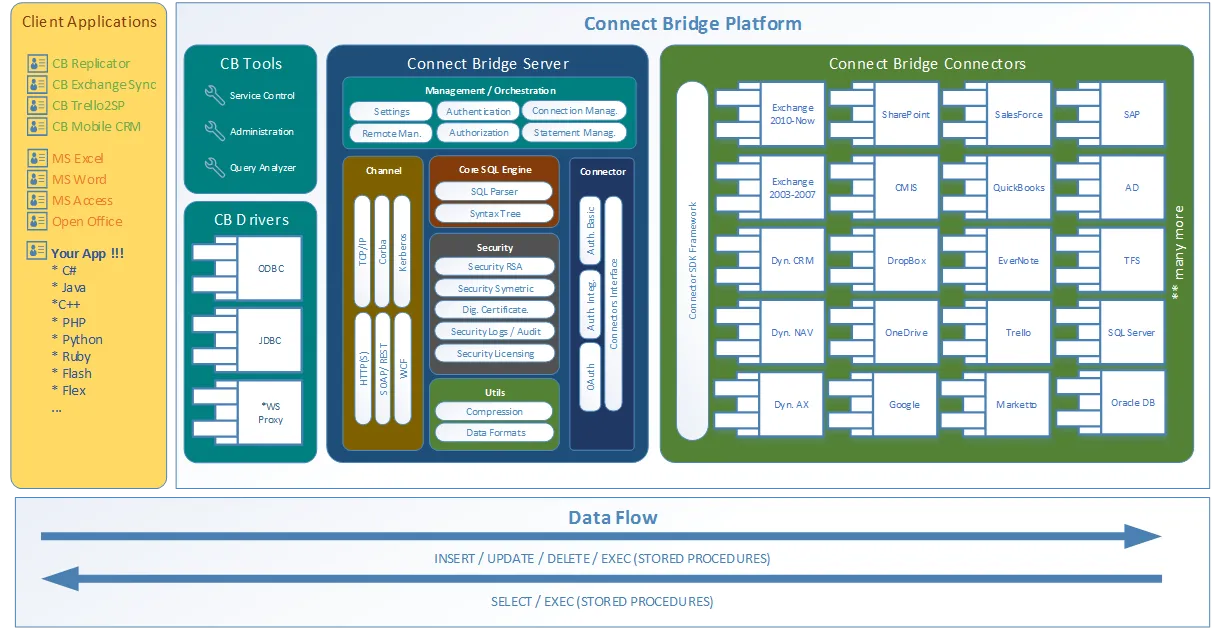
Connect Bridge 統合プラットフォームアーキテクチャ
アーキテクチャ図にあるように、このツールはPythonスクリプト内からMicrosoft SharePointのデータにアクセスできるだけでなく、Microsoft ExchangeやMicrosoft Dynamics CRMとの間でデータを取得/出力することもできます。
目的 - Pythonを使ったSharePointのデータ取得
今回の作業の目的は、Connect Bridgeを経由してSharePointと会話するためのPythonスクリプトを作成することでした。
弊社ではSharePointを使用していますが、同様のロジックで マイクロソフト Exchange またはSalesforceやDynamicsのようなCRMへ。
はじめに...
では、このチュートリアルを始めましょう今回の目的は、SharePointインスタンスにアクセスするシンプルなPythonスクリプトを作成することです。SharePointインスタンスは既に存在していると仮定します(ログイン認証が手元にあることを確認してください)。以下は、あなたが従うべき簡単な手順です。
1.リクエスト フリートライアル とConnect Bridgeをインストールします。
2. インストール Windows用のPython ver.3.7+.スクリプトの作成、実行、デバッグを容易にするために、以下のものを使用しています。 リクリップス 5.2.4ではpydevプラグインを使用していますが、これはもちろん任意です。お好みのエディタを使ってください。
3. インストール パイodbcモジュール 4.0.26+
4. Connect Bridge Management Studioを実行し
4.1. SharePointのアカウントを追加する(Accounts - Add account)。ここで、先ほどの認証情報が必要になります。
4.2. を開く 新規クエリ オプションを指定し コネクションブラウザ.を検索します。 SharePointコネクタ と表示されるまで開いてください。 DefaultConnection.その上で右クリックし 接続文字列の取得.次に、ODBC接続文字列をコピーします。スクリプトに渡すために必要です。
4.3. 新規クエリ]オプションを使用して、SharePointで必要なものにアクセスするクエリをテストしてください。ここでは、クエリの例を示しますが、ここには、SharePointで探しているものを入れてください。をクリックしたら 新規クエリを開いてください。 コネクションブラウザ.を検索します。 SharePointコネクタ と表示されるまで開いてください。 テーブル オプションを使用します。スキーマにSite_Pagesという “テーブル ”が含まれていることがわかります。
SELECT UniqueId, ContentType, Created, Modified, ContentVersion FROM Site_Pages LIMIT 10;
を選択すると、SharePointの最初の10件が選択されます。 サイトページ のリストが表示されます。一見、データベースを直接使っているように見えますが、そうではないことに注意が必要です。
Connect BridgeはAPIにアクセスし、それをあたかもデータベースのように見せているのです。クエリを作成したら、それをコピーしてください。スクリプトに渡すためにも必要です。
ハンズオンスクリプト!
このソリューションの中核であり、同時に唯一のファイルはCBQuery.pyです。ソースコード全体は以下の通りです。コアとなるソリューションを示す70-92行に注目してください。このスクリプトがどのように動作するかの完全な説明は以下の通りです。
#!/usr/local/bin/python3.7
# encoding: utf-8
'''
CBQuery -- query data from, write data to SharePoint
CBQuery is a script that allows to run SQL queries via Connect Bridge ODBC driver
@author: Ana Neto and Michal Hainc
@copyright: 2019
@contact: ana@connecting-soiftware.com
@deffield updated: 04.07.2019
'''
import sys
import os
import pyodbc
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
__all__ = []
__version__ = 0.2
__date__ = '2019-07-04'
__updated__ = '2019-07-04'
DEBUG = 1
TESTRUN = 0
PROFILE = 0
class CLIError(Exception):
'''Generic exception to raise and log different fatal errors.'''
def __init__(self, msg):
super(CLIError).__init__(type(self))
self.msg = "E: %s" % msg
def __str__(self):
return self.msg
def __unicode__(self):
return self.msg
def main(argv=None): # IGNORE:C0111
'''Command line options.'''
if argv is None:
argv = sys.argv
else:
sys.argv.extend(argv)
program_name = os.path.basename(sys.argv[0])
program_version = "v%s" % __version__
program_build_date = str(__updated__)
program_version_message = '%%(prog)s %s (%s)' % (program_version, program_build_date)
program_shortdesc = __import__('__main__').__doc__.split("n")[1]
program_license = '''%s
Created by Ana Neto and Michal Hainc on %s.
Licensed under the Apache License 2.0
http://www.apache.org/licenses/LICENSE-2.0
Distributed on an "AS IS" basis without warranties
or conditions of any kind, either express or implied.
USAGE
''' % (program_shortdesc, str(__date__))
try:
# Setup argument parser
parser = ArgumentParser(description=program_license, formatter_class=RawDescriptionHelpFormatter)
parser.add_argument('connstr')
parser.add_argument('query')
# Process arguments
args = parser.parse_args()
query = args.query
connstr = args.connstr
conn = pyodbc.connect(connstr)
cursor = conn.cursor()
cursor.execute(query)
while 1:
row = None
try:
row = cursor.fetchone()
except:
print(sys.exc_info()[1])
break
if not row:
break
print(row)
except KeyboardInterrupt:
### handle keyboard interrupt ###
return 0
except:
print(sys.exc_info()[1])
#indent = len(program_name) * " "
#sys.stderr.write(program_name + ": " + repr(e) + "n")
#sys.stderr.write(indent + " for help use --help")
return 2
if __name__ == "__main__":
if TESTRUN:
import doctest
doctest.testmod()
if PROFILE:
import cProfile
import pstats
profile_filename = 'CBQuery_profile.txt'
cProfile.run('main()', profile_filename)
statsfile = open("profile_stats.txt", "wb")
p = pstats.Stats(profile_filename, stream=statsfile)
stats = p.strip_dirs().sort_stats('cumulative')
stats.print_stats()
statsfile.close()
sys.exit(0)
sys.exit(main())
スクリプトが何をしているのかを説明します。
- 71~80行目は、コマンドライン引数の入力から変数 connstr と query を取得することに焦点を当てています。このために、pydevのargparseスクリプトテンプレートを使いました。
- 変数 connstr は、ODBC 接続を作成するために pyodbc モジュールに渡す ODBC 接続文字列を保持します。
- 次のステップとして、connに格納されている接続を使用してデータベースカーソルを開きます。
- connに接続が格納されているので、connを使用してデータベースカーソルを開く。
- SQLクエリーを実行します(これはqueryというコマンドラインパラメーターで渡されたクエリーです)。
- 最後に、whileループを使用して、カーソルから行ごとに結果を読み込みます。cursor.fetchoneがNoneを返すと、ループを抜けます。
• ODBCフェッチ中に例外が発生した場合、ループを中断し、問題を出力に表示します
- fetchoneメソッドが成功し、データ行を返したら、生のデータ行をそのまま出力します。xmlやjson、csv...などのデータ交換フォーマットで出力することもできます。また、単純に生のデータ行オブジェクトを使用して、カスタム・タスクを実行するコードを追加することもできます。.
CBQuery.pyスクリプトの実行
CBQuery.pyは2つの位置のコマンドライン引数、connstrとqueryを受け付けることがわかっています。
上記で説明したように、Connect Bridge Management Studioからコピーする必要があります(ポイント4)。
SharePointの連絡先リストを作成して、エントリーを書くことはできますか?
ここで、SharePointにコンタクトリストを作成し、そのリストにコンタクトを作成したいとします。基本的には同じプロセスをたどる必要があるが、クエリを "ストアドプロシージャ" を使用するように変更する。繰り返しますが、この "ストアド・プロシージャ "は、実際にはAPI経由でSharePointにアクセスしますが、指定したSharePointにデータを取得します。以下は、実行する必要のあるクエリーです:
EXEC SP_CREATE_TABLE 'MyContacts', 'This table was created using Connect Bridge', true, 'Contacts';
このクエリは、新しいSharePointリスト(MyContacts)を作成し、SharePointページのクイック起動バーに表示される説明文を付けます。
ここで、SharePointスキーマのConnect Bridge ODBCスキーマ・リフレクションを更新するために、以下のクエリを呼び出す必要がある。これで、新しい “テーブル ”がODBCクライアントから見えるようになります。.
EXEC SP_UPDATE_SCHEMA;
この時点で連絡先リストに連絡先エントリーを挿入することができます。
INSERT INTO MyContacts (FirstName, LastName) VALUES ('Ana', 'Neto');
これで、SharePoint UIに当社のエントリと新しいSharePointリストが表示されるようになるはずです。
以下のクエリを実行することで、先ほど作成したエントリを選択することができます。
SELECT FirstName,LastName FROM MyContacts
共有ドキュメントのアップロードとダウンロード
共有文書をアップロードするには、既存のSharePointリスト「Documents」と「ストアド・プロシージャ」SP_INSERT_SHAREDDOCUMENTを使用します。パラメータは以下の通りです:
- 共有ドキュメント・テーブル名
- ファイル名
- フォルダ(サーバー上の相対パス)
- MIMEタイプ
- ファイルのデータ
以下のステートメントを実行することで、ドキュメントを挿入することができます。
EXEC SP_INSERT_SHAREDDOCUMENT
'Documents',
'hello2.txt',
'/Shared Documents/NewFolder',
'text/plain',
'SGVsbG8gV29ybGQ=';
事前にフォルダの存在を確認したい場合は、ステートメントを実行します。
EXEC SP_ENSURE_FOLDER_PATH
'Documents',
'/NewFolder';
SP_INSERT_SHAREDDOCUMENTを実行した後、ステートメントを実行することで、“Documents ”テーブル内のドキュメントの存在を確認することができます:
SELECT Id,Name FROM Documents;また、ステートメントを実行することで、特定のドキュメントライブラリから特定のドキュメントのバイナリコンタントをダウンロードすることもできます。
EXEC SP_SAVE_SHAREDDOCUMENT_BY_ID 'Documents', 2; この時点で、SharePoint UIで共有ドキュメントの存在を確認することができます。
制約
これまでのところ、ODBC Linuxクライアントライブラリがないため、Windows OSからしかConnect Bridgeツールを使うことができませんでした(それが可能かどうかもわかりません)。ですから、Windowsマシン上でPythonスクリプトを使って遊んでみてください。
結論
PythonでSharePointのデータにアクセスするには、Connect Bridgeの統合プラットフォームを使うと簡単にできることを見てきました。この記事で見てきたことが、Microsoft Dynamics CRM と Microsoft Exchange でも可能だと想像してみてください。はい、Connect Bridgeでも可能ですし、やり方も似ています。
質問がある場合は誰に連絡すればいいですか?

記入例 アナ・ネト, テクニカルアドバイザー Connecting Softwareにて。
"私は1997年からソフトウェア・エンジニアであり、最近は書くことと人前で話すことが好きです。この記事について質問やコメントはありますか?ご意見・ご感想をお待ちしております!"
Comments 1
わかりやすい説明ありがとうございました