
"¿Te has preguntado alguna vez cómo acceder a Microsoft SharePoint en tus scripts de Python?
Este tutorial trata precisamente de eso:
podrás hacerlo de forma sencilla utilizando una herramienta llamada Connect Bridge".
Introducción
Este artículo describe cómo hacer Python se conecta a SharePointes decir, cómo acceder a los datos de los sistemas Microsoft SharePoint (2010, 2013 o 2019) desde dentro de los scripts de lenguaje Python (utilizando la versión 3.7). Las transferencias de datos se realizan a través de la capa ODBC. Hemos logrado esto en Python usando el módulo pyodbc ver. 4.0.26.
Es importante señalar que en este artículo utilizamos un producto comercial llamado Connect Bridge. Esto es, de hecho, lo que hace posible la integración de Python / SharePoint, permitiendo la comunicación de datos de manera que estés seguro de que no estás estropeando el lado SharePoint (y, créeme, esto es MUY importante). Usted puede obtener una prueba gratuita para Connect Bridge, así que puedes probar todo esto por ti mismo.
¿Qué es este "Connect Bridge"?
Me alegro de que lo preguntes. Connect Bridge es una plataforma de integración desarrollada por Connecting Software que permite conectar cualquier software a través de drivers ODBC, drivers JDBC o Web Services. La visión general de la arquitectura de la herramienta está en este diagrama de escenario cliente-servidor.
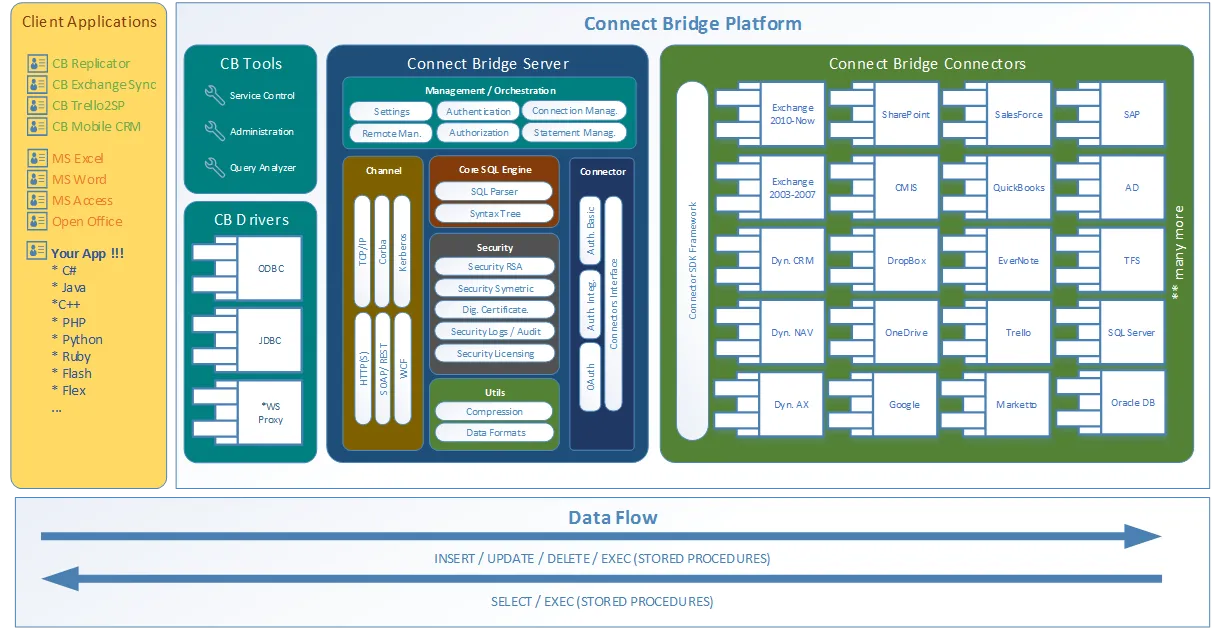
Connect Bridge arquitectura de la plataforma de integración
Como puede ver en el diagrama de arquitectura, la herramienta puede ser usada para acceder no sólo a los datos de Microsoft SharePoint desde dentro de su script Python, sino que también puede agarrar/colocar datos desde/hacia Microsoft Exchange y Microsoft Dynamics CRM entre muchos otros.
El objetivo: obtener datos de la SharePoint mediante Python
El objetivo de nuestro trabajo era crear un script en Python que nos permitiera hablar con el SharePoint a través del Connect Bridge.
Nosotros utilizamos SharePoint, pero es posible utilizar una lógica similar para conectarse a Microsoft Exchange o a un CRM como Salesforce o Dynamics.
Para empezar...
¡Ahora vamos a empezar este tutorial! Nuestro objetivo es crear un sencillo script en Python que acceda a una instancia SharePoint. Asumimos que la instancia SharePoint ya existe (asegúrate de tener tus credenciales de acceso a mano). Estos son los sencillos pasos que debes seguir:
1. Solicite una prueba gratuita e instale el Connect Bridge
2. Instalar Python para Windows ver. 3.7+. Por favor, tenga en cuenta que para facilitar la escritura, ejecución y depuración de mi script hemos utilizado Liclipse 5.2.4 con el plugin pydev, pero esto es, por supuesto, opcional. Puedes usar el editor que quieras.
3. Instalar módulo pyodbc 4.0.26+
4. Ejecute Connect Bridge Management Studio y
4.1. Añade una cuenta para SharePoint (Cuentas - Añadir cuenta). Aquí es donde necesitarás las credenciales que hemos mencionado antes.
4.2. Abrir el Nueva consulta y luego la opción Navegador de conexión. Encuentre el Conector SharePoint y ábralo hasta que vea el Conexión por defecto. Haga clic con el botón derecho del ratón y elija Obtener la cadena de conexión. A continuación, copie la cadena de conexión ODBC. La necesitará para pasarla al script.
4.3. Utilice la opción de Nueva Consulta para probar una consulta que acceda a lo que necesita en SharePoint. Aquí haremos una consulta de ejemplo, pero es aquí donde debe poner lo que busca en SharePoint. Una vez que haya hecho clic en Nueva consultaabrir el Navegador de conexión. Encuentre el Conector SharePoint y ábralo hasta que vea el Tablas opción. Verá que el esquema contiene una "tabla" llamada Site_Pages, por lo que podemos construir nuestra consulta como
SELECT UniqueId, ContentType, Created, Modified, ContentVersion FROM Site_Pages LIMIT 10;
para seleccionar las 10 primeras entradas del SharePoint Páginas del sitio lista. Es importante señalar que, aunque parezca que estamos utilizando directamente una base de datos, no es así.
Connect Bridge accede a la API y la presenta como si fuera una base de datos. Una vez que tengas tu consulta, cópiala, ya que también la necesitarás para pasarla al script.
¡Manos a la obra!
El núcleo y, al mismo tiempo, el único archivo de nuestra solución es CBQuery.py. El código fuente completo está abajo. Por favor, concéntrese en las líneas 70-92 que representan el núcleo de la solución. Una descripción completa de cómo funciona este script se encuentra a continuación.
#!/usr/local/bin/python3.7
# encoding: utf-8
'''
CBQuery -- query data from, write data to SharePoint
CBQuery is a script that allows to run SQL queries via Connect Bridge ODBC driver
@author: Ana Neto and Michal Hainc
@copyright: 2019
@contact: ana@connecting-soiftware.com
@deffield updated: 04.07.2019
'''
import sys
import os
import pyodbc
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
__all__ = []
__version__ = 0.2
__date__ = '2019-07-04'
__updated__ = '2019-07-04'
DEBUG = 1
TESTRUN = 0
PROFILE = 0
class CLIError(Exception):
'''Generic exception to raise and log different fatal errors.'''
def __init__(self, msg):
super(CLIError).__init__(type(self))
self.msg = "E: %s" % msg
def __str__(self):
return self.msg
def __unicode__(self):
return self.msg
def main(argv=None): # IGNORE:C0111
'''Command line options.'''
if argv is None:
argv = sys.argv
else:
sys.argv.extend(argv)
program_name = os.path.basename(sys.argv[0])
program_version = "v%s" % __version__
program_build_date = str(__updated__)
program_version_message = '%%(prog)s %s (%s)' % (program_version, program_build_date)
program_shortdesc = __import__('__main__').__doc__.split("n")[1]
program_license = '''%s
Created by Ana Neto and Michal Hainc on %s.
Licensed under the Apache License 2.0
http://www.apache.org/licenses/LICENSE-2.0
Distributed on an "AS IS" basis without warranties
or conditions of any kind, either express or implied.
USAGE
''' % (program_shortdesc, str(__date__))
try:
# Setup argument parser
parser = ArgumentParser(description=program_license, formatter_class=RawDescriptionHelpFormatter)
parser.add_argument('connstr')
parser.add_argument('query')
# Process arguments
args = parser.parse_args()
query = args.query
connstr = args.connstr
conn = pyodbc.connect(connstr)
cursor = conn.cursor()
cursor.execute(query)
while 1:
row = None
try:
row = cursor.fetchone()
except:
print(sys.exc_info()[1])
break
if not row:
break
print(row)
except KeyboardInterrupt:
### handle keyboard interrupt ###
return 0
except:
print(sys.exc_info()[1])
#indent = len(program_name) * " "
#sys.stderr.write(program_name + ": " + repr(e) + "n")
#sys.stderr.write(indent + " for help use --help")
return 2
if __name__ == "__main__":
if TESTRUN:
import doctest
doctest.testmod()
if PROFILE:
import cProfile
import pstats
profile_filename = 'CBQuery_profile.txt'
cProfile.run('main()', profile_filename)
statsfile = open("profile_stats.txt", "wb")
p = pstats.Stats(profile_filename, stream=statsfile)
stats = p.strip_dirs().sort_stats('cumulative')
stats.print_stats()
statsfile.close()
sys.exit(0)
sys.exit(main())
Esto es lo que hace nuestro script:
- Las líneas 71-80 se centran en obtener las variables connstr y query de la entrada de argumentos de la línea de comandos. Para ello utilizamos la plantilla de script argparse de pydev para facilitarme la vida
- La variable connstr contiene la cadena de conexión ODBC que pasamos al módulo pyodbc para crear una conexión ODBC (almacenada en la variable conn)
- como siguiente paso abrimos un cursor de base de datos utilizando la conexión almacenada en conn
- Teniendo la conexión almacenada en conn abrimos un cursor de base de datos usando conn
- Ejecutamos la consulta SQL (esta es la consulta que se pasó a través del parámetro de línea de comandos llamado query)
- Por último, utilizamos un bucle while para leer los resultados del cursor fila a fila. Cuando cursor.fetchone devuelve None, rompemos el bucle
- Si se produce una excepción durante la obtención ODBC, también rompemos el bucle e imprimimos el problema en la salida
- Si el método fetchone tiene éxito y devuelve una fila de datos, imprimimos la fila de datos tal cual a la salida. Esta fue nuestra elección para esta demo, pero ten en cuenta que esto podría ser cualquier tipo de salida... podríamos formatear como xml o json, csv... o cualquier otro tipo de formato de intercambio de datos. También podríamos simplemente utilizar el objeto fila de datos en bruto para estar en código adicional para realizar tareas personalizadas.
Ejecutando el script CBQuery.py
Sabemos que nuestro CBQuery.py acepta dos argumentos de línea de comando posicional: connstr y query.
Necesitamos copiarlos de Connect Bridge Management Studio como se explicó anteriormente (punto 4).
¿Podemos crear una lista de contactos de SharePoint y escribir una entrada?
Supongamos ahora que queremos crear una lista de contactos en SharePoint y crear un contacto en esa lista. Básicamente tenemos que seguir el mismo proceso pero cambiando la consulta para utilizar un "Stored Procedure". De nuevo, este "Stored Procedure" accederá a SharePoint a través de la API, pero obtendrá los datos en el SharePoint especificado. Esta es la consulta que tenemos que ejecutar:
EXEC SP_CREATE_TABLE 'MyContacts', 'This table was created using Connect Bridge', true, 'Contacts';
La consulta crea una nueva lista SharePoint (MyContacts), con una descripción que se mostrará en la barra de inicio rápido de la página SharePoint.
Ahora tenemos que llamar a la siguiente consulta para actualizar el reflejo del esquema ODBC Connect Bridge del esquema SharePoint. Así, nuestra nueva "tabla" se hace visible para el cliente ODBC.
EXEC SP_UPDATE_SCHEMA;
En este punto podemos insertar una entrada de contacto en nuestra lista de contactos.
INSERT INTO MyContacts (FirstName, LastName) VALUES ('Ana', 'Neto');
Ahora deberías poder ver nuestra entrada y nuestra nueva lista de SharePoint en la interfaz de usuario de SharePoint.
Podemos seleccionar la entrada que acabamos de crear ejecutando la siguiente consulta.
SELECT FirstName,LastName FROM MyContacts
Carga y descarga de documentos compartidos
Para subir un documento compartido, utilizaremos la lista existente SharePoint "Documentos" y el "Stored Procedure" SP_INSERT_SHAREDDOCUMENT. Los parámetros que toma son:
- Nombre de la tabla de documentos compartidos
- Archivo
- Carpeta (ruta relativa, en el servidor)
- Tipo MIME
- Datos del fichero
Podemos insertar el documento ejecutando la siguiente declaración:
EXEC SP_INSERT_SHAREDDOCUMENT
'Documents',
'hello2.txt',
'/Shared Documents/NewFolder',
'text/plain',
'SGVsbG8gV29ybGQ=';
Si quiere comprobar previamente la presencia de la carpeta, puede ejecutar la sentencia:
EXEC SP_ENSURE_FOLDER_PATH
'Documents',
'/NewFolder';
Después de ejecutar el SP_INSERT_SHAREDDOCUMENT podemos comprobar la presencia del documento en la tabla "Documentos" ejecutando la sentencia:
SELECT Id,Name FROM Documents;También podemos descargar el contenido binario de un documento particular de una biblioteca de documentos particular ejecutando la declaración:
EXEC SP_SAVE_SHAREDDOCUMENT_BY_ID 'Documents', 2; En este punto puedes comprobar la existencia del documento compartido en la UI SharePoint
Restricciones
Hasta ahora, hemos podido usar la herramienta Connect Bridge sólo desde sistemas operativos Windows, porque no hay disponible ninguna biblioteca de clientes ODBC Linux (y no estamos seguros de si eso es posible). Así que asegúrese de reproducir sus scripts Python en una máquina Windows.
Conclusión
Hemos visto cómo el acceso a los datos de SharePoint en Python puede hacerse fácilmente usando la plataforma de integración Connect Bridge. Ahora imagina que lo que has visto en este artículo es posible también con Microsoft Dynamics CRM y Microsoft Exchange! Sí, con Connect Bridge esto es posible y la forma de hacerlo es similar.
¿A quién puedo acudir para hacer preguntas?

Por Ana Neto, asesor técnico en Connecting Software.
"Soy ingeniero informático desde 1997, con una afición más reciente por escribir y hablar en público. ¿Tiene alguna pregunta o comentario sobre este artículo? Me encantaría conocer tu opinión, ¡deja un comentario a continuación!"
Comments 1
Gracias por la clara explicación.