
"Haben Sie sich jemals gefragt, wie Sie in Ihren Python-Skripten auf Microsoft SharePoint zugreifen können?
Dieses Tutorial behandelt genau das:
Mit dem Tool Connect Bridge können Sie dies auf einfache Weise tun."
Einführung
Dieser Artikel beschreibt, wie Sie Python verbinden mit SharePoint, d. h. wie man aus Skripten der Sprache Python (unter Verwendung der Version 3.7) auf Daten von Microsoft SharePoint-Systemen (2010, 2013 oder 2019) zugreifen kann. Die Datenübertragungen erfolgen dabei über die ODBC-Schicht. Wir haben dies in Python unter Verwendung der pyodbc-Modul ver. 4.0.26.
Es ist wichtig zu beachten, dass wir in diesem Artikel ein kommerzielles Produkt namens Connect Bridge verwenden. Dies macht die Python/SharePoint-Integration möglich, indem es die Datenkommunikation so ermöglicht, dass Sie sicher sind, dass Sie die SharePoint-Seite nicht durcheinander bringen (und glauben Sie mir, dies ist SEHR wichtig). Sie können eine kostenlose Testversion erhalten für Connect Bridge, damit Sie all dies selbst ausprobieren können.
Was ist dieses "Connect Bridge"?
Ich bin froh, dass Sie fragen! Connect Bridge ist eine von Connecting Software entwickelte Integrationsplattform, mit der Sie jede Software über ODBC-Treiber, JDBC-Treiber oder Webdienste verbinden können. Die allgemeine Übersicht über die Architektur des Tools finden Sie in diesem Client-Server-Szenario-Diagramm.
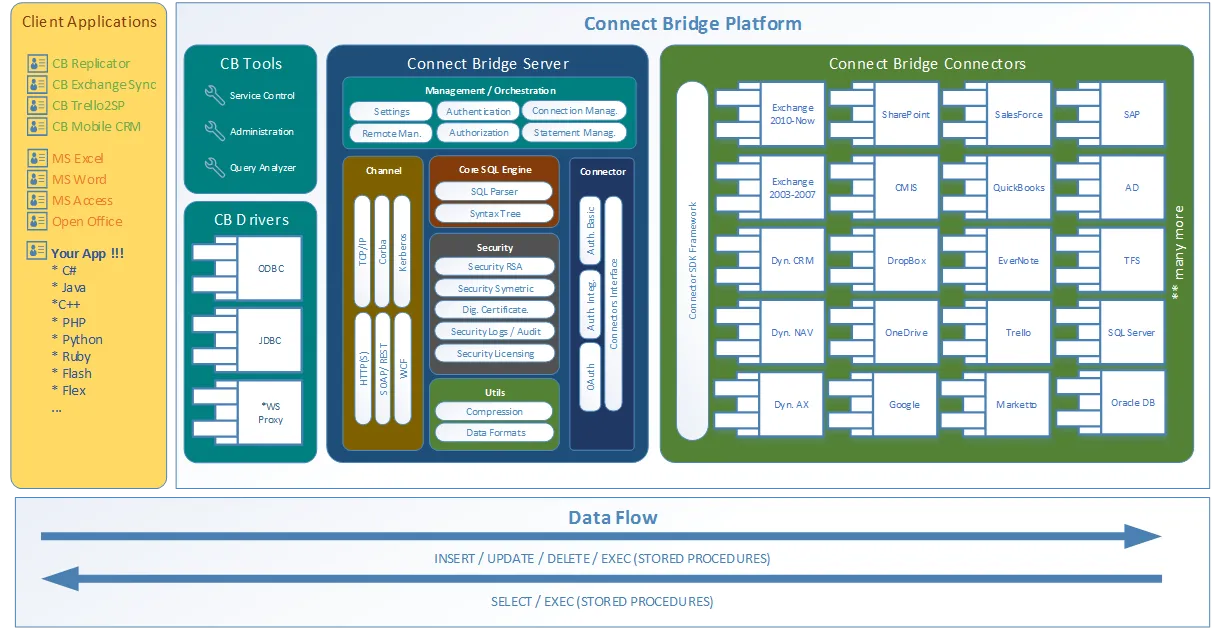
Connect Bridge Integrationsplattform-Architektur
Wie Sie im Architekturdiagramm sehen können, kann das Tool nicht nur für den Zugriff auf Microsoft SharePoint-Daten aus Ihrem Python-Skript heraus verwendet werden, sondern Sie können auch Daten von/zu Microsoft Exchange und Microsoft Dynamics CRM unter vielen anderen abrufen/eingeben.
Das Ziel - Gewinnung von SharePoint-Daten mit Python
Ziel unserer Arbeit war es, ein Python-Skript zu erstellen, das es uns ermöglicht, mit SharePoint über Connect Bridge zu kommunizieren.
Wir verwenden SharePoint, aber es ist möglich, eine ähnliche Logik zu verwenden, um eine Verbindung zu Microsoft Exchange oder zu einem CRM wie Salesforce oder Dynamics.
Erste Schritte...
Beginnen wir nun mit diesem Tutorial! Unser Ziel ist es, ein einfaches Python-Skript zu erstellen, das auf eine SharePoint-Instanz zugreift. Wir gehen davon aus, dass die SharePoint-Instanz bereits existiert (stellen Sie sicher, dass Sie Ihre Anmeldedaten zur Hand haben). Dies sind die einfachen Schritte, die Sie befolgen müssen:
1. Antrag a kostenloser Test und installieren Sie Connect Bridge
2. installieren Python für Windows ver. 3.7+. Bitte beachten Sie, dass wir, um das Schreiben, Ausführen und Debuggen meines Skripts zu erleichtern, Folgendes verwendet haben Liclipse 5.2.4 mit dem pydev-Plugin, aber das ist natürlich optional. Sie können den Editor Ihrer Wahl verwenden.
3. installieren pyodbc-Modul 4.0.26+
4. Führen Sie Connect Bridge Management Studio aus und
4.1. Fügen Sie ein Konto für SharePoint hinzu (Konten - Konto hinzufügen). Hier benötigen Sie die bereits erwähnten Anmeldedaten.
4.2. Öffnen Sie die Neue Abfrage und dann die Option Verbindungs-Browser. Finden Sie die SharePoint Stecker und öffnen Sie es, bis Sie die DefaultConnection. Klicken Sie mit der rechten Maustaste darauf und wählen Sie Verbindungszeichenfolge abrufen. Kopieren Sie dann die ODBC-Verbindungszeichenfolge. Sie benötigen sie, um sie an das Skript weiterzugeben.
4.3. Verwenden Sie die Option "Neue Abfrage", um eine Abfrage zu testen, die auf die von Ihnen benötigten Daten in SharePoint zugreift. Wir werden hier eine Beispielabfrage machen, aber hier sollten Sie eingeben, wonach Sie in SharePoint suchen. Sobald Sie auf Neue Abfrageöffnen Sie die Verbindungs-Browser. Finden Sie die SharePoint Stecker und öffnen Sie es, bis Sie die Tische Option. Sie werden sehen, dass das Schema eine “Tabelle” namens Site_Pages enthält, so dass wir unsere Abfrage wie folgt konstruieren können
SELECT UniqueId, ContentType, Created, Modified, ContentVersion FROM Site_Pages LIMIT 10;
um die ersten 10 Einträge des SharePoints auszuwählen Website-Seiten Liste. Es ist wichtig zu beachten, dass es zwar so aussieht, als würden wir direkt eine Datenbank verwenden, aber das ist nicht der Fall.
Connect Bridge greift auf die API zu und stellt sie dann so dar, als wäre sie eine Datenbank. Sobald Sie Ihre Abfrage haben, kopieren Sie sie, da Sie sie auch benötigen, um sie an das Skript weiterzugeben.
Hände aufs Skript!
Der Kern und gleichzeitig die einzige Datei in unserer Lösung ist CBQuery.py. Der vollständige Quellcode ist unten zu sehen. Bitte konzentrieren Sie sich auf die Zeilen 70-92, in denen die Kernlösung dargestellt wird. Eine vollständige Beschreibung der Funktionsweise dieses Skripts finden Sie weiter unten.
#!/usr/local/bin/python3.7
# encoding: utf-8
'''
CBQuery -- query data from, write data to SharePoint
CBQuery is a script that allows to run SQL queries via Connect Bridge ODBC driver
@author: Ana Neto and Michal Hainc
@copyright: 2019
@contact: ana@connecting-soiftware.com
@deffield updated: 04.07.2019
'''
import sys
import os
import pyodbc
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
__all__ = []
__version__ = 0.2
__date__ = '2019-07-04'
__updated__ = '2019-07-04'
DEBUG = 1
TESTRUN = 0
PROFILE = 0
class CLIError(Exception):
'''Generic exception to raise and log different fatal errors.'''
def __init__(self, msg):
super(CLIError).__init__(type(self))
self.msg = "E: %s" % msg
def __str__(self):
return self.msg
def __unicode__(self):
return self.msg
def main(argv=None): # IGNORE:C0111
'''Command line options.'''
if argv is None:
argv = sys.argv
else:
sys.argv.extend(argv)
program_name = os.path.basename(sys.argv[0])
program_version = "v%s" % __version__
program_build_date = str(__updated__)
program_version_message = '%%(prog)s %s (%s)' % (program_version, program_build_date)
program_shortdesc = __import__('__main__').__doc__.split("n")[1]
program_license = '''%s
Created by Ana Neto and Michal Hainc on %s.
Licensed under the Apache License 2.0
http://www.apache.org/licenses/LICENSE-2.0
Distributed on an "AS IS" basis without warranties
or conditions of any kind, either express or implied.
USAGE
''' % (program_shortdesc, str(__date__))
try:
# Setup argument parser
parser = ArgumentParser(description=program_license, formatter_class=RawDescriptionHelpFormatter)
parser.add_argument('connstr')
parser.add_argument('query')
# Process arguments
args = parser.parse_args()
query = args.query
connstr = args.connstr
conn = pyodbc.connect(connstr)
cursor = conn.cursor()
cursor.execute(query)
while 1:
row = None
try:
row = cursor.fetchone()
except:
print(sys.exc_info()[1])
break
if not row:
break
print(row)
except KeyboardInterrupt:
### handle keyboard interrupt ###
return 0
except:
print(sys.exc_info()[1])
#indent = len(program_name) * " "
#sys.stderr.write(program_name + ": " + repr(e) + "n")
#sys.stderr.write(indent + " for help use --help")
return 2
if __name__ == "__main__":
if TESTRUN:
import doctest
doctest.testmod()
if PROFILE:
import cProfile
import pstats
profile_filename = 'CBQuery_profile.txt'
cProfile.run('main()', profile_filename)
statsfile = open("profile_stats.txt", "wb")
p = pstats.Stats(profile_filename, stream=statsfile)
stats = p.strip_dirs().sort_stats('cumulative')
stats.print_stats()
statsfile.close()
sys.exit(0)
sys.exit(main())
Hier ist, was unser Skript tut:
- In den Zeilen 71-80 geht es darum, die Variablen connstr und query aus der Eingabe der Kommandozeilenargumente zu erhalten. Hierfür haben wir die argparse-Skriptvorlage von pydev verwendet, um mir das Leben zu erleichtern
- Die Variable connstr enthält die ODBC-Verbindungszeichenfolge, die wir an das pyodbc-Modul übergeben, um eine ODBC-Verbindung zu erstellen (gespeichert in der Variable conn)
- Als nächsten Schritt öffnen wir einen Datenbank-Cursor unter Verwendung der in conn gespeicherten Verbindung
- Nachdem die Verbindung in conn gespeichert wurde, öffnen wir einen Datenbank-Cursor mit conn
- Wir führen die SQL-Abfrage aus (dies ist die Abfrage, die über den Befehlszeilenparameter namens query übergeben wurde)
- Schließlich werden die Ergebnisse zeilenweise aus dem Cursor in einer while-Schleife gelesen. Wenn cursor.fetchone keine Ergebnisse liefert, wird die Schleife unterbrochen
• Wenn während des ODBC-Abrufs eine Ausnahme auftritt, brechen wir ebenfalls die Schleife ab und geben das Problem in der Ausgabe aus.
- Wenn die fetchone-Methode erfolgreich ist und eine Datenzeile zurückgibt, geben wir die Rohdatenzeile so wie sie ist in die Ausgabe ein. Dies war unsere Wahl für diese Demo, aber bitte beachten Sie, dass dies jede Art von Ausgabe sein könnte... wir könnten als xml oder json, csv... oder jede andere Art von Datenaustauschformat formatieren. Wir könnten auch einfach das Rohdaten-Zeilenobjekt verwenden, um in weiterem Code benutzerdefinierte Aufgaben durchzuführen.
Ausführen des Skripts CBQuery.py
Wir wissen, dass unsere CBQuery.py zwei positionale Befehlszeilenargumente akzeptiert: connstr und query.
Wir müssen diese, wie oben (Punkt 4) erläutert, aus dem Connect Bridge Management Studio kopieren.
Können wir eine SharePoint-Kontaktliste erstellen und einen Eintrag schreiben?
Nehmen wir nun an, wir wollen eine Kontaktliste in SharePoint erstellen und einen Kontakt in dieser Liste anlegen. Wir müssen im Grunde denselben Prozess befolgen, aber die Abfrage so ändern, dass eine "Stored Procedure" verwendet wird. Auch diese "Stored Procedure" wird über die API auf SharePoint zugreifen, aber die Daten in das von Ihnen angegebene SharePoint übertragen. Hier ist die Abfrage, die wir ausführen müssen:
EXEC SP_CREATE_TABLE 'MyContacts', 'This table was created using Connect Bridge', true, 'Contacts';
Die Abfrage erstellt eine neue SharePoint-Liste (MyContacts) mit einer Beschreibung, die in der Schnellstartleiste der SharePoint-Seite angezeigt wird.
Jetzt müssen wir die folgende Abfrage aufrufen, um die Connect Bridge-ODBC-Schema-Reflexion des SharePoint-Schemas zu aktualisieren. So wird unsere neue “Tabelle” für den ODBC-Client sichtbar.
EXEC SP_UPDATE_SCHEMA;
An dieser Stelle können wir einen Kontakteintrag in unsere Kontaktliste einfügen.
INSERT INTO MyContacts (FirstName, LastName) VALUES ('Ana', 'Neto');
Sie sollten jetzt unseren Eintrag und unsere neue SharePoint-Liste in der SharePoint-UI sehen können.
Wir können den soeben erstellten Eintrag auswählen, indem wir die folgende Abfrage ausführen.
SELECT FirstName,LastName FROM MyContacts
Hoch- und Herunterladen von gemeinsam genutzten Dokumenten
Um ein gemeinsames Dokument hochzuladen, verwenden wir die bestehende SharePoint-Liste “Dokumente” und die "Stored Procedure" SP_INSERT_SHAREDDOCUMENT. Die Parameter, die sie benötigt, sind:
- Name der Tabelle für gemeinsam genutzte Dokumente
- Dateiname
- Ordner (relativer Pfad, auf dem Server)
- MIME-Typ
- Daten für die Datei
Wir können das Dokument einfügen, indem wir die folgende Erklärung ausführen:
EXEC SP_INSERT_SHAREDDOCUMENT
'Documents',
'hello2.txt',
'/Shared Documents/NewFolder',
'text/plain',
'SGVsbG8gV29ybGQ=';
Wenn Sie das Vorhandensein des Ordners vorher überprüfen wollen, können Sie die Anweisung ausführen:
EXEC SP_ENSURE_FOLDER_PATH
'Documents',
'/NewFolder';
Nach Ausführung der SP_INSERT_SHAREDDOCUMENT-Anweisung können wir das Vorhandensein des Dokuments in der Tabelle “Dokumente” überprüfen, indem wir die Anweisung ausführen:
SELECT Id,Name FROM Documents;Wir können auch den binären Inhalt eines bestimmten Dokuments aus einer bestimmten Dokumentenbibliothek herunterladen, indem wir die Erklärung ausführen:
EXEC SP_SAVE_SHAREDDOCUMENT_BY_ID 'Documents', 2; An dieser Stelle können Sie die Existenz des freigegebenen Dokuments in der SharePoint-UI überprüfen
Einschränkungen
Bislang konnten wir das Connect Bridge-Tool nur von Windows-Betriebssystemen aus nutzen, da keine ODBC-Linux-Client-Bibliothek verfügbar ist (und wir sind nicht sicher, ob das überhaupt möglich ist). Stellen Sie also sicher, dass Sie mit Ihren Python-Skripten auf einer Windows-Maschine spielen.
Schlussfolgerung
Wir haben gesehen, wie der Zugriff auf SharePoint-Daten in Python mit Hilfe der Integrationsplattform Connect Bridge leicht möglich ist. Nun stellen Sie sich vor, dass das, was Sie in diesem Artikel gesehen haben, auch mit Microsoft Dynamics CRM und Microsoft Exchange möglich ist! Ja, mit Connect Bridge ist dies möglich, und der Weg dorthin ist ähnlich.
An wen kann ich mich für Fragen wenden?

Durch Ana Neto, Fachberaterin bei Connecting Software.
"Ich bin seit 1997 Software-Ingenieur, und seit kurzem schreibe ich gerne und halte öffentliche Vorträge. Haben Sie Fragen oder Kommentare zu diesem Artikel? Ich würde mich über Ihr Feedback freuen. Hinterlassen Sie unten einen Kommentar!"
Comments 1
Vielen Dank für die klare Erklärung!