
"Você já se perguntou como acessar o Microsoft SharePoint em seus scripts Python?
Este tutorial aborda exatamente isso:
você será capaz de fazê-lo de uma maneira fácil, usando uma ferramenta chamada Connect Bridge".
Introdução
Este artigo descreve como fazer Python ligar ao SharePointO sistema Microsoft SharePoint (2010, 2013 ou 2019), ou seja, como aceder aos dados dos sistemas Microsoft SharePoint a partir de scripts em linguagem Python (utilizando a versão 3.7). As transferências de dados são feitas através da camada ODBC. Conseguimos isto em Python usando a módulo de pyodbc ver. 4.0.26.
É importante notar que neste artigo utilizamos um produto comercial chamado Connect Bridge. Isto é, de facto, o que torna possível a integração Python / SharePoint, ao permitir a comunicação de dados de uma forma que de certeza não compromete a integrida do lado do SharePoint (e, acredite em mim, isto é MUITO importante). Pode iniciar um período de teste gratuito com o Connect Bridge, para que possa experimentar tudo isto por si mesmo.
O que é este "Connect Bridge"?
Fico contente por teres perguntado! Connect Bridge é uma plataforma de integração desenvolvida pelo Connecting Software que permite conectar qualquer software através de drivers ODBC, drivers JDBC ou Web Services. A visão geral da arquitetura da ferramenta está neste diagrama de cenário cliente-servidor.
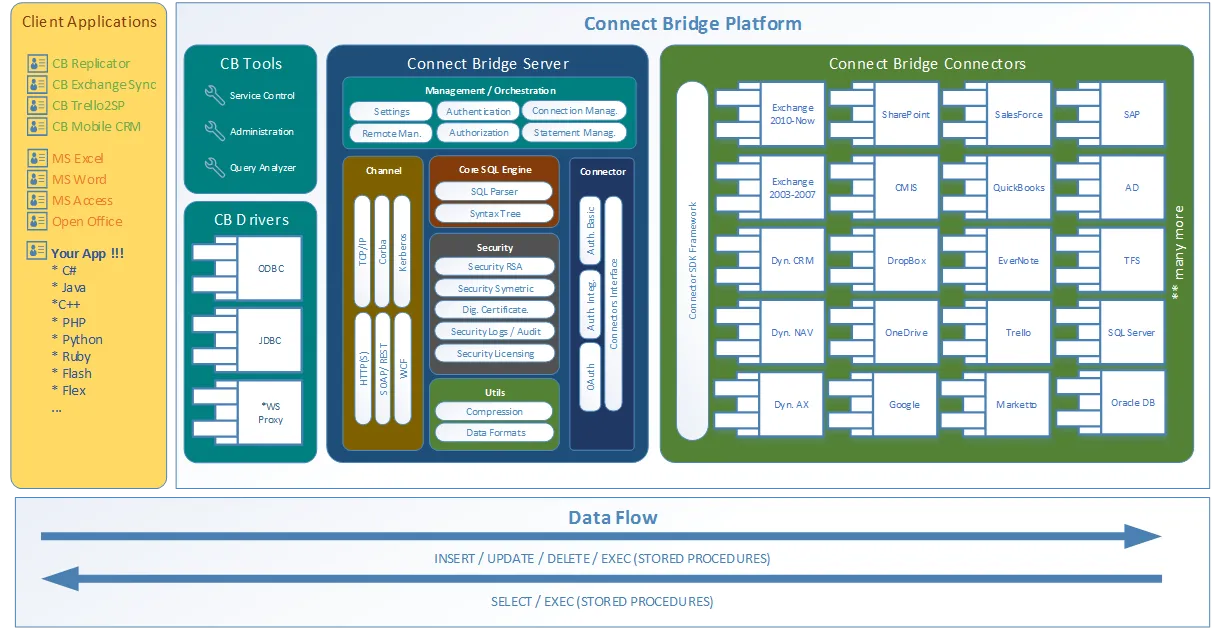
Connect Bridge arquitetura da plataforma de integração
Como pode ver no diagrama, a ferramenta pode ser usada para aceder não apenas aos dados do Microsoft SharePoint a partir do seu script Python, mas também pode ir buscar/portar dados de/para o Microsoft Exchange e Microsoft Dynamics CRM, entre muitos outros.
O objectivo - obter dados SharePoint usando o Python
O objectivo do nosso trabalho era criar um script Python que nos permitisse falar com o SharePoint via Connect Bridge.
Nós usamos SharePoint, mas é possível usar lógica similar para conectar a Microsoft Exchange ou a um CRM como o Salesforce ou Dynamics.
A começar...
Agora vamos começar este tutorial! Nosso objetivo é criar um script Python simples que acesse uma instância de SharePoint. Assumimos que a instância SharePoint já existe (certifique-se que tem as suas credenciais de login em mãos). Estes são passos simples que você precisa seguir:
1. Peça uma avaliação gratuita e instale o Connect Bridge
2. Instale o Python para Windows ver. 3.7+. Por favor note que para facilitar a escrita, execução e depuração do meu script, temos usado Liclipse 5.2.4 com o plugin pydev, mas isto é, é claro, opcional. Você pode usar um editor à sua escolha.
3. Instale o módulo de pyodbc 4.0.26+
4. Execute o Connect Bridge Management Studio e
4.1. Adicionar uma conta para SharePoint (Contas - Adicionar conta). Aqui é onde você vai precisar das credenciais que mencionamos anteriormente.
4.2. Abra o Nova Consulta e depois a opção Navegador de Conexão. Encontre o Conector SharePoint e abra-o até ver o DefaultConnection. Clique com o botão direito do mouse sobre ele e escolha Obter cadeia de ligação. Depois copie a cadeia de ligação ODBC. Você vai precisar dela para passá-la para o script.
4.3. Use a opção Nova Consulta para testar uma consulta que irá acessar o que você precisa no SharePoint. Vamos fazer uma consulta de exemplo aqui, mas é aqui que deve colocar o que procura no SharePoint. Uma vez que você tenha clicado em Nova Consultaabra o Navegador de Conexão. Encontre o Conector SharePoint e abra-o até ver o Tabelas opção. Verá que o esquema contém uma "tabela" chamada Site_Pages, pelo que podemos construir a nossa consulta como
SELECT UniqueId, ContentType, Created, Modified, ContentVersion FROM Site_Pages LIMIT 10;
para seleccionar as 10 primeiras entradas de SharePoint's Páginas do site lista. É importante notar que embora pareça que estamos usando uma base de dados diretamente, não é o caso.
Connect Bridge está acessando a API e depois apresentando-a como se fosse uma base de dados. Uma vez que você tenha sua consulta, copie-a, pois você também vai precisar dela para passá-la para o script.
Finalmente o script de Python!
O núcleo e, ao mesmo tempo, o único arquivo em nossa solução é o CBQuery.py. O código fonte completo está abaixo. Por favor, concentre-se nas linhas 70-92 que retratam a solução do núcleo. Uma descrição completa de como este script funciona está abaixo.
#!/usr/local/bin/python3.7
# encoding: utf-8
'''
CBQuery -- query data from, write data to SharePoint
CBQuery is a script that allows to run SQL queries via Connect Bridge ODBC driver
@author: Ana Neto and Michal Hainc
@copyright: 2019
@contact: ana@connecting-soiftware.com
@deffield updated: 04.07.2019
'''
import sys
import os
import pyodbc
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
__all__ = []
__version__ = 0.2
__date__ = '2019-07-04'
__updated__ = '2019-07-04'
DEBUG = 1
TESTRUN = 0
PROFILE = 0
class CLIError(Exception):
'''Generic exception to raise and log different fatal errors.'''
def __init__(self, msg):
super(CLIError).__init__(type(self))
self.msg = "E: %s" % msg
def __str__(self):
return self.msg
def __unicode__(self):
return self.msg
def main(argv=None): # IGNORE:C0111
'''Command line options.'''
if argv is None:
argv = sys.argv
else:
sys.argv.extend(argv)
program_name = os.path.basename(sys.argv[0])
program_version = "v%s" % __version__
program_build_date = str(__updated__)
program_version_message = '%%(prog)s %s (%s)' % (program_version, program_build_date)
program_shortdesc = __import__('__main__').__doc__.split("n")[1]
program_license = '''%s
Created by Ana Neto and Michal Hainc on %s.
Licensed under the Apache License 2.0
http://www.apache.org/licenses/LICENSE-2.0
Distributed on an "AS IS" basis without warranties
or conditions of any kind, either express or implied.
USAGE
''' % (program_shortdesc, str(__date__))
try:
# Setup argument parser
parser = ArgumentParser(description=program_license, formatter_class=RawDescriptionHelpFormatter)
parser.add_argument('connstr')
parser.add_argument('query')
# Process arguments
args = parser.parse_args()
query = args.query
connstr = args.connstr
conn = pyodbc.connect(connstr)
cursor = conn.cursor()
cursor.execute(query)
while 1:
row = None
try:
row = cursor.fetchone()
except:
print(sys.exc_info()[1])
break
if not row:
break
print(row)
except KeyboardInterrupt:
### handle keyboard interrupt ###
return 0
except:
print(sys.exc_info()[1])
#indent = len(program_name) * " "
#sys.stderr.write(program_name + ": " + repr(e) + "n")
#sys.stderr.write(indent + " for help use --help")
return 2
if __name__ == "__main__":
if TESTRUN:
import doctest
doctest.testmod()
if PROFILE:
import cProfile
import pstats
profile_filename = 'CBQuery_profile.txt'
cProfile.run('main()', profile_filename)
statsfile = open("profile_stats.txt", "wb")
p = pstats.Stats(profile_filename, stream=statsfile)
stats = p.strip_dirs().sort_stats('cumulative')
stats.print_stats()
statsfile.close()
sys.exit(0)
sys.exit(main())
Aqui está o que o nosso script está a fazer:
- As linhas 71-80 concentram-se em obter as variáveis connstr e query a partir da entrada de argumentos da linha de comando. Para isso, usámos o modelo de script argparse do pydev para facilitar a minha vida
- A variável connstr contém a cadeia de ligação ODBC que passamos para o módulo pyodbc para criar uma ligação ODBC (armazenada na variável conn)
- Como passo seguinte, abrimos um cursor de base de dados utilizando a ligação armazenada em conn
- Tendo a ligação armazenada em conn, abrimos um cursor de base de dados utilizando conn
- Executamos a consulta SQL (esta é a consulta que foi passada através do parâmetro de linha de comando chamado query)
- Finalmente, usamos um loop while para ler os resultados do cursor linha por linha. Quando cursor.fetchone retorna None, interrompemos o loop
- Se ocorrer uma exceção durante a pesquisa ODBC, também interrompemos o ciclo e imprimimos o problema na saída
- Se o método fetchone for bem-sucedido e retornar uma linha de dados, imprimimos a linha de dados brutos como está na saída. Esta foi a nossa escolha para esta demonstração, mas note que poderia ser qualquer tipo de saída... poderíamos formatar como xml ou json, csv... ou qualquer outro tipo de formato de troca de dados. Também poderíamos simplesmente usar o objeto de linha de dados brutos para ser usado em código adicional para executar tarefas personalizadas.
Executando o script CBQuery.py
Sabemos que o nosso CBQuery.py aceita dois parâmetros posicionais: connstr e query.
Precisamos de copiá-los do Connect Bridge Management Studio como explicado acima (ponto 4).
E se eu quiser criar uma lista de contatos SharePoint e escrever nela?
Suponhamos agora que queremos criar uma lista de contactos no SharePoint e criar um contacto nessa lista. Basicamente, temos de seguir o mesmo processo, mas alterar a consulta para utilizar um "Stored Procedure". Mais uma vez, este "Stored Procedure" estará, de facto, a aceder ao SharePoint através da API, mas estará a obter os dados para o SharePoint que especificou. Aqui está a consulta que precisamos de executar:
EXEC SP_CREATE_TABLE 'MyContacts', 'This table was created using Connect Bridge', true, 'Contacts';
A consulta cria uma nova lista do SharePoint (MyContacts), com uma descrição que aparecerá na barra de lançamento rápido da página do SharePoint.
Agora temos de chamar a seguinte consulta para atualizar a reflexão do esquema ODBC Connect Bridge do esquema SharePoint. Assim, a nossa nova "tabela" fica visível para o cliente ODBC.
EXEC SP_UPDATE_SCHEMA;
Neste ponto, podemos inserir uma entrada de contacto na nossa lista de contactos.
INSERT INTO MyContacts (FirstName, LastName) VALUES ('Ana', 'Neto');
Deverá agora poder ver a nossa entrada e a nossa nova lista do SharePoint entrando no SharePoint.
Podemos selecionar a entrada que acabamos de criar, executando a seguinte consulta.
SELECT FirstName,LastName FROM MyContacts
Carregamento e descarregamento de documentos partilhados
Para carregar um documento partilhado, utilizaremos a lista "Documents" existente no SharePoint e o "Stored Procedure" SP_INSERT_SHAREDDOCUMENT. Os parâmetros necessários são:
- Nome da tabela de documentos partilhados
- Nome de ficheiro
- Pasta (caminho relativo, no servidor)
- Tipo MIME
- Dados para o ficheiro
Podemos inserir o documento executando a seguinte declaração:
EXEC SP_INSERT_SHAREDDOCUMENT
'Documents',
'hello2.txt',
'/Shared Documents/NewFolder',
'text/plain',
'SGVsbG8gV29ybGQ=';
Se você quiser verificar a presença da pasta com antecedência, você pode executar a declaração:
EXEC SP_ENSURE_FOLDER_PATH
'Documents',
'/NewFolder';
Depois de executar o SP_INSERT_SHAREDDOCUMENT, podemos verificar a presença do documento na tabela "Documents" executando a instrução:
SELECT Id,Name FROM Documents;Também podemos baixar o conteúdo binário de um determinado documento de uma determinada biblioteca de documentos, executando a declaração:
EXEC SP_SAVE_SHAREDDOCUMENT_BY_ID 'Documents', 2; Chegado a este ponto você pode verificar a existência do documento partilhado entrando no SharePoint.
Restrições
Até agora, vimos como utilizar a ferramenta Connect Bridge, mas usámos apenas sistemas operativos Windows, porque não existe uma biblioteca cliente ODBC Linux disponível (e não temos a certeza se isso é sequer possível). Portanto, certifique-se de usar estes scripts Python numa máquina Windows.
Conclusão
Vimos como aceder a dados do SharePoint em Python de forma fácil usando a plataforma de integração do Connect Bridge. Mas o que o que você viu neste artigo é possível também com o Microsoft Dynamics CRM e o Microsoft Exchange! Sim, com o Connect Bridge é possível e pode ser feito de forma semelhante.
A quem posso dirigir-me para fazer perguntas?

Por Ana Neto, consultor técnico em Connecting Software.
"Sou engenheiro de software desde 1997, com uma paixão mais recente pela escrita e por falar em público. Tem alguma pergunta ou comentário sobre este artigo? Gostaria muito de receber o seu feedback, deixe um comentário abaixo!"
Comments 1
Obrigado pela explicação clara!