
"Vous êtes-vous déjà demandé comment accéder à Microsoft SharePoint dans vos scripts Python ?
C'est précisément ce à quoi répond ce tutoriel :
vous pourrez le faire de manière simple en utilisant un outil appelé Connect Bridge."
Introduction
Cet article décrit comment faire Connexion Python à SharePointc'est-à-dire comment accéder aux données des systèmes Microsoft SharePoint (2010, 2013 ou 2019) à partir de scripts en langage Python (en utilisant la version 3.7). Les transferts de données sont effectués via la couche ODBC. Nous avons réalisé cela en Python en utilisant le module pyodbc ver. 4.0.26.
Il est important de noter que dans cet article, nous utilisons un produit commercial appelé Connect Bridge. C'est en fait ce qui rend possible l'intégration Python / SharePoint, en permettant la communication de données d'une manière qui vous assure de ne pas perturber le côté SharePoint (et, croyez-moi, c'est TRÈS important). Vous pouvez obtenir un essai gratuit pour le Connect Bridge, vous pouvez donc essayer tout cela par vous-même.
Qu'est-ce que ce "Connect Bridge" ?
Je suis heureux que vous demandiez ! Connect Bridge est une plateforme d'intégration développée par Connecting Software qui vous permet de connecter n'importe quel logiciel par le biais de pilotes ODBC, JDBC ou de services Web. L'aperçu général de l'architecture de l'outil se trouve sur ce schéma de scénario client-serveur.
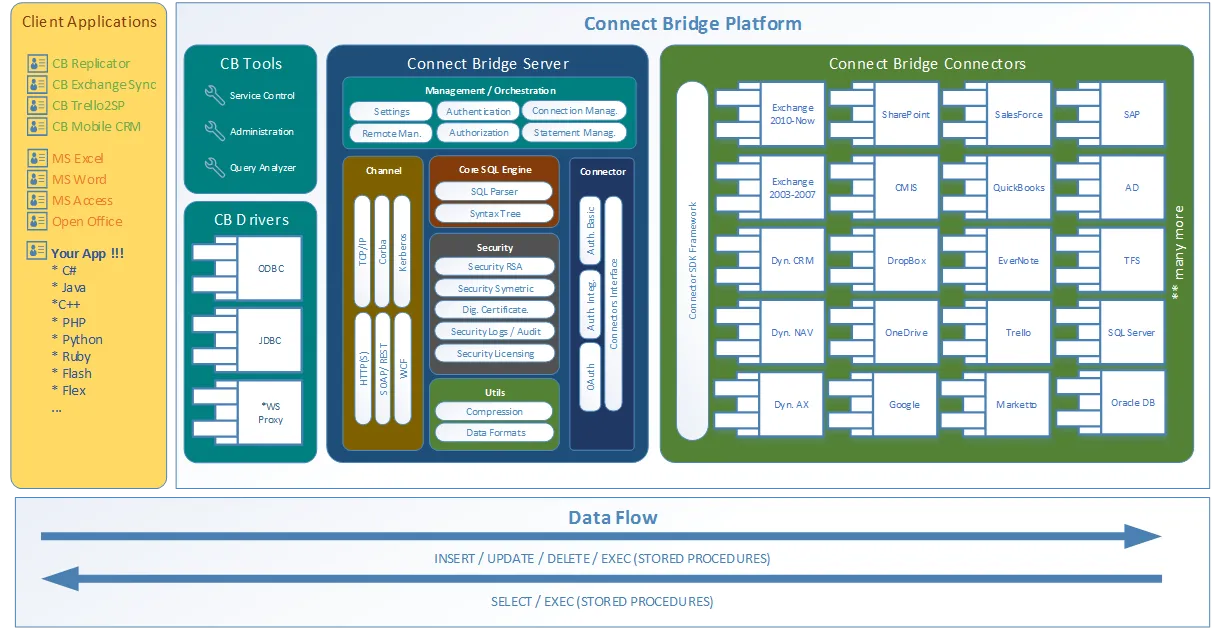
Connect Bridge l'architecture de la plate-forme d'intégration
Comme vous pouvez le voir sur le diagramme d'architecture, l'outil peut être utilisé pour accéder non seulement aux données de Microsoft SharePoint à partir de votre script Python, mais vous pouvez également saisir/enregistrer des données de Microsoft Exchange et de Microsoft Dynamics CRM, parmi beaucoup d'autres.
L'objectif - obtenir des données SharePoint en utilisant Python
Le but de notre travail était de créer un script Python qui nous permettrait de parler à SharePoint via Connect Bridge.
Nous utilisons SharePoint, mais il est possible d'utiliser une logique similaire pour se connecter à Microsoft Exchange ou à un CRM comme Salesforce ou Dynamics.
Pour commencer...
Commençons maintenant ce tutoriel ! Notre objectif est de créer un simple script Python qui accède à une instance SharePoint. Nous supposons que l'instance SharePoint existe déjà (assurez-vous d'avoir vos identifiants de connexion à portée de main). Voici les étapes simples que vous devez suivre :
1. Demander un essai gratuit et installer Connect Bridge
2. Installez Python pour Windows ver. 3.7+. Veuillez noter que pour faciliter l'écriture, l'exécution et le débogage de mon script, nous avons utilisé les outils suivants Liclipse 5.2.4 avec le plugin pydev, mais cela est bien sûr facultatif. Vous pouvez utiliser l'éditeur de votre choix.
3. Installez module pyodbc 4.0.26+
4. Exécution du studio de gestion Connect Bridge et
4.1. Ajoutez un compte pour SharePoint (Comptes - Ajouter un compte). C'est ici que vous aurez besoin des informations d'identification dont nous avons parlé précédemment.
4.2. Ouvrez le Nouvelle requête et ensuite l'option Navigateur de connexion. Trouvez le Connecteur SharePoint et ouvrez-le jusqu'à ce que vous voyiez le DefaultConnection. Cliquez sur le bouton droit de la souris et choisissez Obtenir la chaîne de connexion. Copiez ensuite la chaîne de connexion ODBC. Vous en aurez besoin pour la transmettre au script.
4.3. Utilisez l'option Nouvelle requête pour tester une requête qui vous permettra d'accéder à ce dont vous avez besoin dans SharePoint. Nous allons donner un exemple de requête ici, mais c'est ici que vous devez indiquer ce que vous recherchez dans SharePoint. Une fois que vous avez cliqué sur Nouvelle requête, ouvrez le Navigateur de connexion. Trouvez le Connecteur SharePoint et ouvrez-le jusqu'à ce que vous voyiez le Tableaux (option). Vous verrez que le schéma contient une "table" appelée Site_Pages et que nous pouvons donc construire notre requête comme suit
SELECT UniqueId, ContentType, Created, Modified, ContentVersion FROM Site_Pages LIMIT 10 ;
pour sélectionner les 10 premières entrées de la liste de SharePoint. Pages du site liste. Il est important de noter que, bien qu'il semble que nous utilisions directement une base de données, ce n'est pas le cas.
Connect Bridge accède à l'API et la présente ensuite comme s'il s'agissait d'une base de données. Une fois que vous avez votre requête, copiez-la, car vous en aurez également besoin pour la transmettre au script.
Les mains sur le script !
Le fichier central et, en même temps, le seul fichier de notre solution est CBQuery.py. Le code source complet est ci-dessous. Veuillez vous concentrer sur les lignes 70-92 qui décrivent la solution de base. Vous trouverez ci-dessous une description complète du fonctionnement de ce script.
#!/usr/local/bin/python3.7
# encoding: utf-8
'''
CBQuery -- query data from, write data to SharePoint
CBQuery is a script that allows to run SQL queries via Connect Bridge ODBC driver
@author: Ana Neto and Michal Hainc
@copyright: 2019
@contact: ana@connecting-soiftware.com
@deffield updated: 04.07.2019
'''
import sys
import os
import pyodbc
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
__all__ = []
__version__ = 0.2
__date__ = '2019-07-04'
__updated__ = '2019-07-04'
DEBUG = 1
TESTRUN = 0
PROFILE = 0
class CLIError(Exception):
'''Generic exception to raise and log different fatal errors.'''
def __init__(self, msg):
super(CLIError).__init__(type(self))
self.msg = "E: %s" % msg
def __str__(self):
return self.msg
def __unicode__(self):
return self.msg
def main(argv=None): # IGNORE:C0111
'''Command line options.'''
if argv is None:
argv = sys.argv
else:
sys.argv.extend(argv)
program_name = os.path.basename(sys.argv[0])
program_version = "v%s" % __version__
program_build_date = str(__updated__)
program_version_message = '%%(prog)s %s (%s)' % (program_version, program_build_date)
program_shortdesc = __import__('__main__').__doc__.split("n")[1]
program_license = '''%s
Created by Ana Neto and Michal Hainc on %s.
Licensed under the Apache License 2.0
http://www.apache.org/licenses/LICENSE-2.0
Distributed on an "AS IS" basis without warranties
or conditions of any kind, either express or implied.
USAGE
''' % (program_shortdesc, str(__date__))
try:
# Setup argument parser
parser = ArgumentParser(description=program_license, formatter_class=RawDescriptionHelpFormatter)
parser.add_argument('connstr')
parser.add_argument('query')
# Process arguments
args = parser.parse_args()
query = args.query
connstr = args.connstr
conn = pyodbc.connect(connstr)
cursor = conn.cursor()
cursor.execute(query)
while 1:
row = None
try:
row = cursor.fetchone()
except:
print(sys.exc_info()[1])
break
if not row:
break
print(row)
except KeyboardInterrupt:
### handle keyboard interrupt ###
return 0
except:
print(sys.exc_info()[1])
#indent = len(program_name) * " "
#sys.stderr.write(program_name + ": " + repr(e) + "n")
#sys.stderr.write(indent + " for help use --help")
return 2
if __name__ == "__main__":
if TESTRUN:
import doctest
doctest.testmod()
if PROFILE:
import cProfile
import pstats
profile_filename = 'CBQuery_profile.txt'
cProfile.run('main()', profile_filename)
statsfile = open("profile_stats.txt", "wb")
p = pstats.Stats(profile_filename, stream=statsfile)
stats = p.strip_dirs().sort_stats('cumulative')
stats.print_stats()
statsfile.close()
sys.exit(0)
sys.exit(main())
Voici ce que fait notre scénario :
- Les lignes 71-80 se concentrent sur l'obtention des variables connstr et query à partir des arguments de la ligne de commande. Pour cela, nous avons utilisé le modèle de script argparse de pydev pour me faciliter la vie
- La variable connstr contient la chaîne de connexion ODBC que nous transmettons au module pyodbc pour créer une connexion ODBC (stockée dans la variable conn).
- L'étape suivante consiste à ouvrir un curseur de base de données à l'aide de la connexion stockée dans le fichier conn.
- La connexion étant stockée dans conn, nous ouvrons un curseur de base de données à l'aide de conn.
- Nous exécutons la requête SQL (il s'agit de la requête qui a été transmise via le paramètre de ligne de commande nommé query).
- Enfin, nous utilisons une boucle while pour lire les résultats du curseur ligne par ligne. Lorsque cursor.fetchone renvoie None, nous interrompons la boucle
- Si une exception se produit au cours de l'extraction ODBC, nous interrompons également la boucle et imprimons le problème en sortie.
- Si la méthode fetchone réussit et renvoie une ligne de données, nous imprimons la ligne de données brute telle quelle sur la sortie. C'est ce que nous avons choisi pour cette démo, mais notez qu'il pourrait s'agir de n'importe quel type de sortie... nous pourrions formater en xml ou json, csv... ou tout autre type de format d'échange de données. Nous pourrions aussi simplement utiliser l'objet ligne de données brutes pour l'intégrer dans un code ultérieur afin d'effectuer des tâches personnalisées.
Exécution du script CBQuery.py
Nous savons que notre CBQuery.py accepte deux arguments de ligne de commande positionnelle : connstr et query.
Nous devons les copier à partir de Connect Bridge Management Studio comme expliqué ci-dessus (point 4).
Pouvons-nous créer une liste de contacts SharePoint et rédiger une entrée ?
Supposons maintenant que nous voulions créer une liste de contacts dans SharePoint et créer un contact dans cette liste. Nous devons essentiellement suivre le même processus, mais modifier la requête pour utiliser une "procédure stockée". Une fois de plus, cette "procédure stockée" accède en fait à SharePoint via l'API, mais elle récupère les données dans la SharePoint que vous avez spécifiée. Voici la requête que nous devons exécuter :
EXEC SP_CREATE_TABLE 'MyContacts', 'This table was created using Connect Bridge', true, 'Contacts';
La requête crée une nouvelle liste SharePoint (MyContacts), avec une description qui apparaîtra dans la barre de lancement rapide de la page SharePoint.
Nous devons maintenant appeler la requête suivante pour mettre à jour le reflet du schéma ODBC Connect Bridge du schéma SharePoint. Ainsi, notre nouvelle "table" devient visible pour le client ODBC.
EXEC SP_UPDATE_SCHEMA;
À ce stade, nous pouvons insérer une entrée de contact dans notre liste de contacts.
INSERT INTO MyContacts (FirstName, LastName) VALUES ('Ana', 'Neto');
Vous devriez maintenant pouvoir voir notre entrée et notre nouvelle liste SharePoint dans l'interface utilisateur SharePoint.
Nous pouvons sélectionner l'entrée que nous venons de créer en exécutant la requête suivante.
SELECT FirstName,LastName FROM MyContacts
Chargement et téléchargement de documents partagés
Pour télécharger un document partagé, nous utiliserons la liste existante SharePoint "Documents" et la "Procédure stockée" SP_INSERT_SHAREDDOCUMENT. Les paramètres qu'elle prend sont :
- Nom de la table des documents partagés
- Nom de fichier
- Dossier (chemin relatif, sur le serveur)
- Type MIME
- Données pour le fichier
Nous pouvons insérer le document en faisant la déclaration suivante :
EXEC SP_INSERT_SHAREDDOCUMENT
'Documents',
'hello2.txt',
'/Shared Documents/NewFolder',
'text/plain',
'SGVsbG8gV29ybGQ=';
Si vous voulez vérifier la présence du dossier au préalable, vous pouvez exécuter l'instruction :
EXEC SP_ENSURE_FOLDER_PATH
'Documents',
'/NewFolder';
Après avoir exécuté la commande SP_INSERT_SHAREDDOCUMENT, nous pouvons vérifier la présence du document dans la table "Documents" en exécutant la commande :
SELECT Id,Name FROM Documents;Nous pouvons également télécharger le contant binaire d'un document particulier à partir d'une bibliothèque de documents particulière en lançant la déclaration :
EXEC SP_SAVE_SHAREDDOCUMENT_BY_ID 'Documents', 2; A ce stade, vous pouvez vérifier l'existence du document partagé dans l'interface utilisateur SharePoint
Contraintes
Jusqu'à présent, nous n'avons pu utiliser l'outil Connect Bridge qu'à partir des systèmes d'exploitation Windows, car aucune bibliothèque client ODBC Linux n'est disponible (et nous ne sommes même pas sûrs que cela soit possible). Assurez-vous donc de jouer avec vos scripts Python sur une machine Windows.
Conclusion
Nous avons vu comment l'accès aux données SharePoint en Python peut être facilement réalisé en utilisant la plate-forme d'intégration Connect Bridge. Maintenant, imaginez que ce que vous avez vu dans cet article est également possible avec Microsoft Dynamics CRM et Microsoft Exchange ! Oui, avec Connect Bridge, c'est possible et la manière de le faire est similaire.
À qui puis-je m'adresser pour toute question ?

Par Ana Neto, conseiller technique à Connecting Software.
"Je suis ingénieur logiciel depuis 1997, et depuis peu, j'aime écrire et parler en public. Avez-vous des questions ou des commentaires sur cet article ? J'aimerais avoir votre avis, laissez un commentaire ci-dessous !"
Comments 1
Merci pour cette explication claire !